华为“毕昇”编译器模糊测试——项目二期
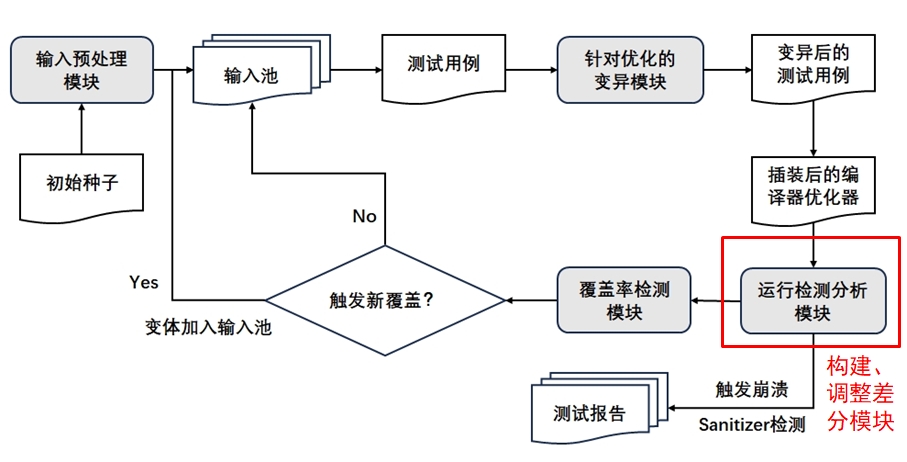
在项目一期中,我们构建了针对编译优化模块的变异策略以服务于模糊测试,但该模块只能产生一系列 ir,这些 ir 经指定的优化模块处理后可以得到优化后的 ir,在优化处理过程中,内存的溢出或直接崩溃往往暗示了优化模块可能存在的 bug。
但这种检测是不够的,因为这种严重的 crash 在发生的可能性上往往很小,故我们需要对 ir 的执行结果进行差分测试,对比优化前后的 ir 的执行结果,若有差异则也可进行对比溯源,找到可能存在的 bug。
优化测试模块总体架构
输出指令插入算法
在我们变异生成的 ir 中,虽然有一些指令的处理逻辑,但这些被处理的变量没有输出,这样我们的差分模块就只能打开内存进行执行结果对比(难度太高,反正我短期内找不到识别内存中有效变量的值并进行差分的办法),故我们还是采用传统的输出对比的方式。
这就涉及输出指令(printf)的插入,直观的,不能为所有中间变量都插入输出指令,这会破坏优化位点,导致无意义的优化测试,故我设计出基于以下插入规则的启发式算法:
- 一条指令可以被输出仅当:
- 不为 void 类型
- 不是 Terminal 指令
- 一条指令输出收益较大仅当:
- 其没有 User 或其 User 类型为 void
- 依据其 Use 关系建树
- 指令本身为节点,用到的 Value 为子节点
- 当前节点为 Call 指令则深入函数或直接为该边的长度赋予一个较大值
- 当前节点没有 Use 对象或 Use 对象都为常数 或 全局值,则停止
- 计算树的高度,越高则收益越大
- 不在循环内(加分项)
- 收益的衡量和整个程序的 BasicBlock 数量相关,和指令所在块的指令条数相关。
这个算法为 ir 内一些“靠后”的变量产生输入,能更具代表性地反映程序的正确性。
错误过滤器
由于我们要对 ir 进行执行操作,这就对 ir 的合理性提出了更高的要求,这里定义“不合理的 ir”为:
- 无法通过 llvm 自带的合理性检查
- ir 执行过程中崩溃 (Core Dump)
- ir 执行时间过长
- ir 导致差分模块的误判
- 优化前的 ir 执行结果不确定
- 异常导致 ir 执行结果未写入输出文件
- 优化后的 ir 执行结果不确定(poison 值)
- 未定义行为导致意料之外的执行结果
针对不同类型的 ir 及其细分情况,其初步的(有的比较生硬)解决办法是:
- ir 无法通过 llvm 自动检查 Assertion
- GlobalValue is not external
原因:在 llvm 源码中有专门对 GlobalValue 的检查,如果不初始化会被归入 External 的全局值类型
解决:在代码中 GlobalValue 声明时使用 Internal 的 LinkageType,并给予初始值,这两步缺一不可 - Phi is not at the top of block
原因:llvm 自带的随机指令插入变异可能在 Phi 指令前插入一些指令
解决:在指令插入变异的函数末尾添加 Phi 指令提前的逻辑 - XXX is not dominate all its use
原因:可能有很多种,目前解决的是插入循环导致一些指令的 dom 关系被破坏
解决:在插入循环时维护好前驱后继(特别是 Phi 指令和跳转指令)的关系,保证不破坏支配关系
- GlobalValue is not external
- 误判
- before 执行结果不确定
原因:未定义行为
解决:将 before 的 ir 执行两次,若结果不一致直接舍弃该变异体(处理比较消极,后续从源码上修改) - 异常导致 before 执行结果无法写入文件
- 除/模 0 异常
解决:对于 除/模 类指令检查第二操作数- 若为常数且为 0 则修改
- 若不为常数,则替换为该值 + 7 (需修改)
- 移位异常
原因:移位操作数过大或为负数
解决:对于移位类指令检查第二操作数- 若为常数且过大或为负数则修改
- 若不为常数,则插入取模指令限制第二操作数
- GEP 指令异常
原因:GEP 指令偏移量为溢出或为负数
解决:获取其操作的指针的空间长度,对偏移量进行取模(Urem) - alloca 指令异常
原因:alloca 分配的空间长度为负数
解决:对于 alloca 指令检查第一操作数- 若为常数且为负数则修改为 16
- 若不为常数则直接置为 16(因为自动生成的 alloca 指令几乎不会用来存储数组) (需修改)
- store 指令异常
- store 写常量空间
原因:store 向一些存储常量的空间存入值
解决:溯源检查 store 写入的空间,若不能存入则删除此 store 指令 - store 写溢出
原因:store 写的字段长度大于分配的空间的长度
解决:- 若空间皆为常量:检索对应 alloca 指令分配类型的长度,与 store 写入的数据类型长度对比,若溢出则删除该指令
- 否则:对写入目标的 alloca 指令进行 8 字节对齐,可以避免写溢出 (需修改)
- store 写常量空间
- call 指令调用 printf 函数的参数被修改
原因:llvm 自带的插入指令的变异会为行插入的指令找一个 User
解决:防止 call 指令成为该机制找到的 User
- 除/模 0 异常
- 溢出导致 after 打印 poison 值
原因:使用随机数导致各种算术指令的溢出
解决:- 最大程度避免使用随机数,现已实现语义相同的变异(拆分指令和合并后的指令执行后的结果相同)
- 对极易溢出的指令(移位),使用模数的方法进行限制
- 检查优化后的 ir 中有无 poison 值,若有则丢弃该变异体
- before 执行结果不确定
- 崩溃(core dump)
- 段错误(核心已转储)
- call 指令的对象和参数被改动
原因:llvm 自带的插入指令的变异会为行插入的指令找一个 User
解决:防止 call 指令成为该机制找到的 User - store 指令存入的值位数大于空间长度
原因:llvm 自带的插入指令的 sink 机制会生成一些存储值到其 alloca 出的空间的 store 指令
解决:不使用已有的 alloca 指令,为新的值新建 alloca 指令
- call 指令的对象和参数被改动
- 段错误(核心已转储)
- ir 执行时间过长
- 循环次数过多
解决:限制循环类变异插入循环的循环次数 - 循环深度过大
解决:循环类变异插入循环前检查深度 - 死循环
解决:限时执行(需修改)
- 循环次数过多
执行和结果对比
这里比较直接,先使用 c++ 执行一些命令行将 .ll 文件编译链接为可执行文件:
bool runAndSaveResult(const std::string &filename, llvm::Module &M, bool isBefore) {
// 1. 将 M 转化为 .ll 文件
int fd = 0;
std::error_code EC = llvm::sys::fs::openFileForWrite("./result/executing.ll", fd);
if (!EC) {
raw_fd_ostream OS(fd, true);
M.print(OS, nullptr);
OS.close();
} else {
errs() << "Failed to open output file: " << EC.message() << "\n";
return false;
}
// 2. 使用 llc 将 .ll 文件编译成目标文件
std::string objFile = "./result/executing.o";
std::string llFile = "./result/executing.ll";
std::string llcCommand = "llc " + llFile + " -opaque-pointers -filetype=obj -o " + objFile;
int llcResult = std::system(llcCommand.c_str());
if (llcResult != 0) {
errs() << "Failed to execute llc command\n";
return false;
}
// 3. 使用 clang 将目标文件链接成可执行文件
std::string executable = "./result/executing";
std::string clangCommand = "clang " + objFile + " -o " + executable + " -no-pie";
int clangResult = std::system(clangCommand.c_str());
if (clangResult != 0) {
errs() << "Failed to execute clang command\n";
return false;
}
// 4. 执行可执行文件,并将结果写入指定文件
std::string execCommand = "timeout 20s " + executable + " > " + filename;
int execResult = std::system(execCommand.c_str());
if (execResult != 0) {
return false;
}
if (isBefore) {
std::string execCommandAddition = "timeout 20s " + executable + ">" + "./result/before_addition.txt";
int execResultAddition = std::system(execCommandAddition.c_str());
} else {
std::string execCommandAddition = "timeout 20s " + executable + ">" + "./result/after_addition.txt";
int execResultAddition = std::system(execCommandAddition.c_str());
}
return true;
}
然后是对比输出的逻辑:
bool compareResults(const std::string &file1, const std::string &file2) {
// 打开第一个文件
llvm::ErrorOr<std::unique_ptr<llvm::MemoryBuffer>> File1BufferOrErr =
llvm::MemoryBuffer::getFile(file1);
if (!File1BufferOrErr) {
errs() << "Error opening file: " << file1 << "\n";
abort();
return false;
}
std::unique_ptr<llvm::MemoryBuffer> File1Buffer = std::move(*File1BufferOrErr);
// 打开第二个文件
llvm::ErrorOr<std::unique_ptr<llvm::MemoryBuffer>> File2BufferOrErr =
llvm::MemoryBuffer::getFile(file2);
if (!File2BufferOrErr) {
errs() << "Error opening file: " << file2 << "\n";
abort();
return false;
}
std::unique_ptr<llvm::MemoryBuffer> File2Buffer = std::move(*File2BufferOrErr);
// 比较两个文件的内容是否相同
return File1Buffer->getBuffer() == File2Buffer->getBuffer();
}
本阶段使编译器优化模块测试部分已经可以初步使用,但仍存在一些问题,其中最重要的是防止错误指令的生成,令人头痛的种种错误情况的收敛性仍然需要评估。


