华为“毕昇”编译器模糊测试——项目一期
暑期“毕昇杯”比赛的获奖经历使本人在课设实验中获得了宝贵的开摆机会,又经机缘巧合,遂加入华为“毕昇”编译器模糊测试联合项目组。
我负责的是该编译器优化器模块的模糊测试;在第一阶段的工作中,我们尚无权限接触“毕昇”编译器源码,故在该编译器基于的 llvm 经典编译器源码上进行架构设计和相关实验。
环境要求
- Ubuntu 20.04 (或一些较新版本的 linux 系统)
- 推荐 4 GB 内存
- 预留至少 30 GB 的存储空间
- GNU 工具包
- ninja 工具
- 集成开发环境(可选)
源码获取和安装
源码下载
解压后置于根目录或根目录下的子目录即可(这样保证了磁盘分区足够)
源码编译和运行
进入源码根目录,运行:
cmake -S llvm -B build -G "Unix Makefiles" -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DLLVM_USE_SANITIZER=Address -DLLVM_USE_SANITIZE_COVERAGE=On -DLLVM_BUILD_RUNTIME=Off -DCMAKE_BUILD_TYPE=Release
cmake --build build
等待即可(时间较长)
编译完成后,所有模块的可执行文件位于 build/bin 目录下,查阅相关使用文档,在该目录下执行相关运行指令即可。
优化器模糊测试设计
整体架构
编译优化器模糊测试的整体架构如图所示,其可以自动生成或由用户指定输入一系列初始输入文件(初始种子)置于输入池中,由变异模块采取不同的变异策略对输入文件进行有针对性的变异,检测分析模块依据编译器优化模块对这些变异文件的执行结果,生成测试报告,并依据 libFuzzer 覆盖率统计导向选取其中对当前测试目标有较新覆盖的变异文件放入输入池中进一步变异以继续测试。
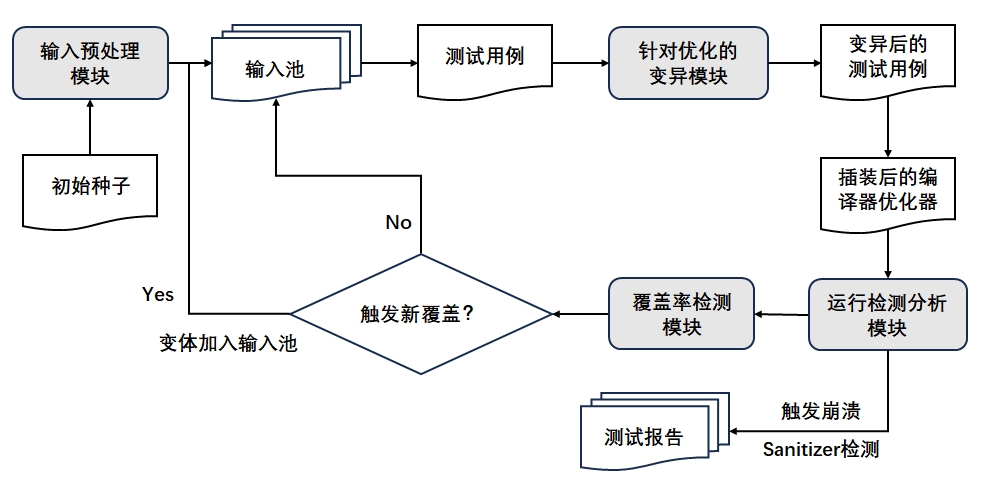
在编译优化器模糊测试架构下,主要可分为4个子模块:
(1) 输入预处理模块
处理用户命令行输入,对用户提供的含有初始输入 llvm 字节码文件的初始种子目录进行扫描,依次读入文件供给变异模块;若用户提供的文件非法或不存在,则调用样例自动生成器。
样例自动生成器的初步设计是事先给定一个较大的语料库,当需要调用自动生成模块时,从语料库中随机选出指令文件并进行随机的初步简单变异放入输入池中;值得注意的是,后续优化测试中生成的具有较新覆盖的变异文件也会可能被填充进入语料库中。
(2) 针对优化的变异模块
对初始的输入文件进行针对优化导向的变异;具体的,变异模块内部采取多种针对不同优化策略的变异策略(具体变异策略详见变异设计),每个变异策略具有一定的权重,变异时会依据设定的权重随机对每个输入文件进行多次多种变异,生成较多的变异体供给编译器的优化模块执行。
(3) 运行检测分析模块
对编译器优化器执行的结果进行评估,若执行时崩溃或执行后得到的优化 IR 无法正常执行,则可以说明在变异模块不引入错误的情况下,变异针对的优化策略的程序中可能存在缺陷,模块会记录优化程序和优化后的 IR 的执行日志信息,结合 Sanitizer 检测,标注可能存在缺陷的编译器优化模块,生成测试报告。
(4) 覆盖率检测模块
将 libFuzzer 和待测试的编译器优化模块链接,通过在编译器优化模块代码中插桩,检测优化模块执行变异体的执行路径,从而统计测试的覆盖率,如果覆盖率提高,证明执行的变异体是较优的,将该变异体放入测试输入池中,同时也可选择将其放入语料库中以供随机测试输入的生成。
变异策略设计
针对具体优化的设计方法
下面的内容中,先指出针对的变异策略,代码部分分割线上方是变异前的代码,下方是变异后的代码;可以发现,经过我们的变异设计,代码中产生了更多可触发相关优化的位点,如此增加针对优化的测试强度。
块内变异算子
- InstrCombine
%a = add i32 %b, constant
---------------------------------
%a1 = add i32 %b, constant_0
%a2 = add i32 %a1, constant_1
……
%a = add i32 %an, constant_n
// constant = constant_0 + …… + constant_n
- FuncInline
%a = add i32 %b, %c
---------------------------------
define dso_local i32 @sum(i32 %d1, i32 %d2){
%d3 = add i32 %d1, %d2
ret i32 %d3
}
%a = call i32 @sum(i32 %b, i32 %c)
- DeadCodeEleminate
instr1
instr2
---------------------------------
instr1
DEAD_CODE_UNIT
instr2
DEAD_CODE_UNIT:
通用的:
* 新建与程序无关的变量,进行无效计算
* 引入对主程序无影响的冗余函数
* 构造无意义循环特化的:
* 如果 instr1/instr2 为计算类指令,可插入一些互逆的冗余运算,但要保证运算值的一致性
* 如果 instr2 为 store/load 类指令,可在其之前插入若干对该指令对象的 store/load 指令CalculateSimplify
%a = add i32 %b, constant
--------------------------------
%c = ALU_OP i32 constant_1, constant_2
%a = add i32 %b, %c
// constant_1 ALU_OP constant_2 = constant
- GlobalValueLocalize
%a = add i32 %b, %c
--------------------------------
@GLB_a = dso_local global i32 0
%a = add i32 %b, %c
store i32 %a, i32* @GLB_a
instr replace all %a with @GLB_a
函数内变异算子
- GVN & GCM
%a = add %b, %c
……
instr use %a
-------------------------
%a = add %b, %c
……
%d = add %b, %c
instr replace all %a with %d
// 需保证 %b, %c 的值在中间没有被改变 (store)
- LoopInvariantCodeMotion
BB2:
br label %BB3
BB3:
%l15 = phi i32 [ 0 , %BB2 ], [ %l9 , %BB4 ]
%l4 = icmp slt i32 %l15, 10
br i1 %l4, label %BB4, label %BB5
BB4:
call void @putint(i32 %l15)
%l9 = add i32 %l15, 1
br label %BB3
BB5:
ret i32 0
------------------------------------------------
@GLB_a = dso_local global [1 x i32] [i32 1]
BB2:
br label %BB3
BB3:
%l23 = phi i32 [ 0 , %BB2 ], [ %l7 , %BB4 ]
%l21 = phi i32 [ 0 , %BB2 ], [ %l15 , %BB4 ]
%l4 = icmp slt i32 %l21, 10
br i1 %l4, label %BB4, label %BB5
BB5:
ret i32 0
BB4:
/*----------------------------------------------------*/
%l6 = getelementptr inbounds [1 x i32], [1 x i32]* @GLB_a, i32 0, i32 0
%l7 = load i32, i32* %l6
/*----------------------------------------------------*/
call void @putint(i32 %l7)
call void @putint(i32 %l21)
%l15 = add i32 %l21, 1
br label %BB3
- LoopFusion
BB2:
br label %BB3
BB3:
%l20 = phi i32 [ 0 , %BB2 ], [ %l12 , %BB4 ]
%l18 = phi i32 [ 0 , %BB2 ], [ %l9 , %BB4 ]
%l6 = icmp slt i32 %l20, 10
br i1 %l6, label %BB4, label %BB5
BB5:
ret i32 0
BB4:
%l9 = add i32 %l18, 1
%l12 = add i32 %l20, 1
br label %BB3
-------------------------------------------------
BB2:
br label %BB3
BB3:
%l23 = phi i32 [ 0 , %BB2 ], [ %l7 , %BB4 ]
%l4 = icmp slt i32 %l23, 10
br i1 %l4, label %BB4, label %BB5
BB5:
br label %BB6
BB6:
%l25 = phi i32 [ 0 , %BB5 ], [ %l17 , %BB7 ]
%l14 = icmp slt i32 %l25, 10
br i1 %l14, label %BB7, label %BB8
BB8:
ret i32 0
BB7:
%l17 = add i32 %l25, 1
br label %BB6
BB4:
%l7 = add i32 %l23, 1
br label %BB3
策略在 llvm 源码上的添加
在 llvm 中,模糊测试的框架已经为我们搭建完成,但其中采用的变异策略十分随机,过于简单,我们可以在其源码中添加我们编写的针对优化的变异策略进行效果测试。
我们以针对 FuncInline 的变异策略为例:
首先,找到 llvm/include/llvm/FuzzMutate/IRMutator.h 仿照已经建立的变异策略新建变异策略类:
//针对函数内联优化
class ForFuncInlineIRStrategy : public IRMutationStrategy {
public:
uint64_t getWeight(size_t CurrentSize, size_t MaxSize,
uint64_t CurrentWeight) override {
return 100000;
}
using IRMutationStrategy::mutate;
void mutate(BasicBlock &BB, RandomIRBuilder &IB) override;
};
这里将权重设置为 10000 以确保随机采用变异策略时几乎每次都能触发此策略,这便于我们后续运行查看效果。
下一步,找到 llvm/lib/FuzzMutate/IRMutator.cpp 添加新建策略类的 mutate 方法的定义:
//针对函数内联
static int v_block_id = 1;
static int v_func_id = 1;
void llvm::ForFuncInlineIRStrategy::mutate(BasicBlock &BB,
RandomIRBuilder &IB) {
for (auto &inst : BB.getInstList()) {
if (!inst.isBinaryOp()) {
continue;
}
int opcode = inst.getOpcode();
Value *val1 = NULL;
Value *val2 = NULL;
Use *oprands = inst.getOperandList();
for (Use *oprand = oprands, *E = inst.getNumOperands() + oprands;
oprand != E; ++oprand) {
if (oprand == oprands) {
val1 = oprand->get();
} else {
val2 = oprand->get();
break;
}
}
if (val1 == NULL || val2 == NULL) {
continue;
}
Type *types[2] = {val1->getType(), val2->getType()};
FunctionType *funcType = FunctionType::get(inst.getType(), ArrayRef<Type *>(types, 2), false);
Function *func = Function::Create(funcType,
llvm::GlobalValue::LinkageTypes::ExternalLinkage, "my_func_" + std::to_string(v_func_id++), inst.getModule());
llvm::LLVMContext &llvmContext = inst.getModule()->getContext();
BasicBlock *block = BasicBlock::Create(llvmContext, "my_block_" + std::to_string(v_block_id++), func);
Instruction *newInst = inst.clone();
newInst->setName("my_new_inst_" + std::to_string(v_block_id));
block->getInstList().push_back(newInst);
Function::arg_iterator arg_it = func->arg_begin();
newInst->setOperand(0, &(*arg_it));
arg_it++;
newInst->setOperand(1, &(*arg_it));
IRBuilder<> builder(llvmContext);
ReturnInst *retInst = builder.CreateRet(newInst);
block->getInstList().push_back(retInst);
Value *params[2] = {val1, val2};
CallInst* callInst = builder.CreateCall(func, ArrayRef<Value *>(params, 2), "", NULL);
callInst->insertAfter(&inst);
inst.replaceAllUsesWith(callInst);
inst.eraseFromParent();
return ; //wait to opt, we have to ret here cause erase will damage the iterator!!!
}
}
这里需要使用很多 llvm 提供的接口来改变 IR 的结构,推荐使用 IDE 进行代码编辑或查阅相关文档。
最后,找到 llvm/tools/llvm-opt-fuzzer/llvm-opt-fuzzer.cpp 将新建的策略放入策略表中以供测试时选取:
Strategies.push_back(std::make_unique());
至此,我们为 llvm 的模糊测试架构添加了一个新的变异策略。
策略的运行和测试
我们修改了 llvm 的源码,显然,我们不想再经历一次整个项目的 make;因此,我们可以采用 ninja 工具:
- 进入源码根目录,运行:
cmake -S llvm -B buildnin -G Ninja -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DLLVM_USE_SANITIZER=Address -DLLVM_USE_SANITIZE_COVERAGE=On -DLLVM_BUILD_RUNTIME=Off -DCMAKE_BUILD_TYPE=Release
- 进入源码根目录下的 buildnin 目录,运行:
ninja llvm-opt-fuzzer
- 编译完成后,在 buildnin/bin 下即可找到 llvm-opt-fuzzer 的可执行文件
至此,我们可以试运行以测试刚刚的变异策略是否有效:
- 在 buildnin/bin 下运行:
./llvm-opt-fuzzer test -ignore_remaining_args=1 -mtriple x86_64 -passes instcombine
其中 -passes 后指明了测试针对的优化,也可以更换成其他的来进行测试。
该命令可以手动终止(Ctrl + z)
- 此时 buildnin/bin 下生成的 test 文件中包含了一系列字节码文件,使用 build/bin 目录下的 llvm-dis 将其反汇编为 .ll 文件即可查看变异效果:
./llvm-dis ~/LLVM/llvm-project-llvmorg-15.0.4/buildnin/bin/test/*
其中的 test 目录所在位置依据存放的实际位置来编写。
针对函数内联的变异测试中,其中一个文件经过多次变异前后的效果如下:
用户接口设计
测试器运行接口
该编译优化器模糊测试工具提供命令行接口供用户进行针对优化测试或全局优化测试,命令行初步设计如下:
llvm-opt-test [-d DIRECTORY] [-passes (OPT_STRATEGY)*]
其中 –d DIRECTORY 指示了初始输入文件所在目录的位置,若缺省则默认为当前目录,-passes (OPT_STRATEGY)* 指示了测试针对的若干具体优化策略,若缺省则表示对所有优化策略进行测试,即全局优化测试。
具体的,OPT_STRATEGY初步设计的部分可选参数如下:
| OPT_STRATEGY | 说明 |
|---|---|
| 缺省 | 默认对所有优化策略进行测试 |
| * | 对所有优化策略进行测试 |
| dce | 针对死代码删除优化的测试 |
| cprog | 针对常量传播优化的测试 |
| gcm | 针对全局代码移动优化的测试 |
| instcombine | 针对指令合并优化的测试 |
| funcinline | 针对函数内联优化的测试 |
| glbopt | 针对全局变量或函数优化集合的测试 |
| loopopt | 针对循环相关优化的测试 |
新增针对测试接口
在编译器的实际测试中,开发人员也可能新增一些编译优化策略,该编译优化器模糊测试工具也提供了命令行接口使用户可以自定义OPT_STRATEGY选项的内容以针对新增的优化策略进行测试,命令行初步设计如下:
add-test-pass –pass NEW_STRATEGY –cmd CMD_TO_OPEN_STRATEGY
其中,NEW_STRATEGY为用户自定义的新优化策略的字符串表示,由数字、字母和下划线构成,可用于测试命令的OPT_STRATEGY选项,CMD_TO_OPEN_STRATEGY为用户提供的在运行待测试编译器时打开该优化的指令接口(可以理解成编译待测试的编译器时打开相关优化以得到具备这种优化功能的可执行文件的编译选项)。
后续工作
- 继续完成剩余的针对各种优化的测试的变异策略
- 着手依照测试架构搭建测试工具的框架



